This was a tough one that required alot of work with Microsoft Partner Support over many WEEKS, but the answer is surprisingly simple.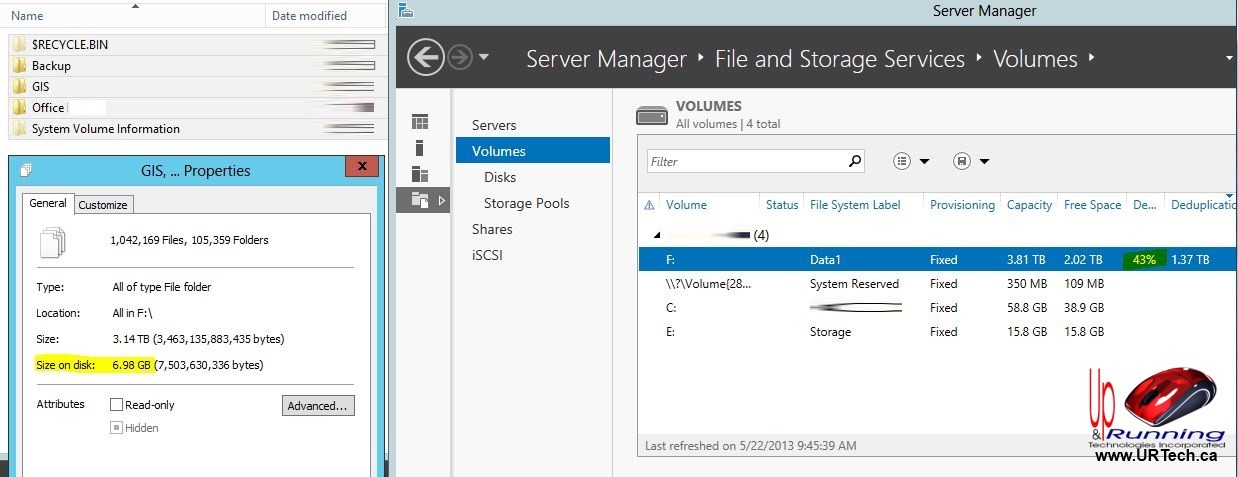
PROBLEM:
When I right click and check the Properties on a data deduplicated folder (on Server 2012) the SIZE ON DISK shows some incredibly small numbers compared to the SIZE. In the example screen shot, you can see 3.14TB shows as 6.98GB ON DISK… which is nutty 99.98 percent. However the Deduplication % shown in SERVER MANAGER > FILE & STORAGE > VOLUMES is a more believable 43%. How can this be.
ANSWER:
Server 2012 Data Deduplication service MOVES duplicated ‘chunks’ (bit level blocks of data) into the SYSTEM VOLUME INFORMATION folder and so Windows Explorer (and presumably other tools) just look at the residual non-duplicated chunks (like each files meta-data) that is still stored in the folder you think it is stored in. That is why Windows Explorer provides accurate but massively misleading information on the size of the files\folders in question.
For more detail, look at the graphic and explaination below (which I took directly from my new best friend Green Yi at MS Partner Support thread).
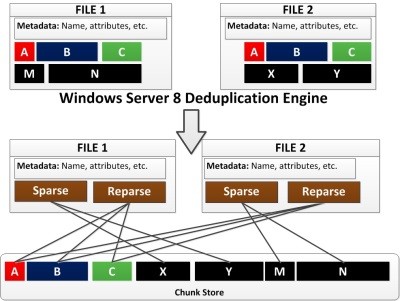
Generally, the basic construct of Windows deduplication is that it is a variable chunk that ranges between 32 KB and 128 KB. Chunks that are a duplicate are copied to a chunk store that is managed by Windows and kept in the System Volume Information section of the disk.
Here is an image shows Windows being applied to two files.
In the image, data blocks A, B, and C are deduplication candidates. When the deduplication engine runs, an eligible file has its deduplication blocks copied into the chunk store. From there, the file has two dimensions of its data: a spare and a reparse region. The reparse regions call to the chunk store to access the common chunks or deduplicated data.
When we enabled the Data Deduplication on the drive, if a file is fully deduplicated, it will only consume 4.00 KB on disk. This is only for the metadata sections of the files, and all of the reparse (and no parse) regions would be in the chunk store. So, if most files on the drive has the same metadata on the disk, the deduplication will help save a lot disk on the drive. In addition, from the article “Monitor and Report for Data Deduplication”, it indicate that “When you use File Explorer to view the properties of a deduplicated file, you will see that Size shows the logical size of the file, andSize on Disk shows the true physical allocation to that file. Size on Disk is less than the actual file size because deduplication has moved the contents of the file to a common chunk store and replaced the original file with an NTFS reparse point stub and metadata. Use the Measure-DedupFileMetadata Windows PowerShell cmdlet to determine how much space could be freed if you deleted particular files or folders.”


1 Comment
SOLVED: How to Enable, Configure and Test Data Deduplication in Windows Server 2012 - Up & Running Technologies Calgary · August 8, 2013 at 4:34 pm
[…] Why Does Data Deduplication Have SIZE ON DISK and DEDUPLICATION Numbers NOT Match […]